In This Section
4C Partners












'Crunching Numbers and Comparing Costs' by Matthew Addis
 I was at the JISC digifest and got to catch-up with the 4C project through a great presentation that Neil Grindley did in one of the workshops [3].
I was at the JISC digifest and got to catch-up with the 4C project through a great presentation that Neil Grindley did in one of the workshops [3].
A few things struck me in Neil's talk. The first was the statement that cost modelling isn't actually the problem anymore - there's enough stuff out there already on calculating costs so that people can just get on and do it if they really want to. Rather the problem is one of cost comparison. There is huge diversity of schemes used by organisations to classify where costs are incurred, e.g. ingest, curation, storage, access, and then how to account for these costs, e.g. direct and indirect, capex and opex, labour and infrastructure. This makes comparison hard - it's age old problem of apples and oranges [4] and some pear-shaped [5] fruit for good measure. This resonates with my experience too - people who measure or estimate their costs get a lot of reassurance, and sometimes solace, by being able to compare their numbers with those from other people. Are they too high? Are they too low? Is there something missing? Could they be reduced - or maybe should they be inflated to provide contingency? This is where the CCEx should be invaluable and may well become the single most useful output of the project - a set of real world yardsticks. It is not easy to get people to provide their data of course, so it will be interesting to see how the community can be rallied or incentivised to contribute, but if they can, and the CCEx gathers momentum as a result, then it will become a great resource.
Suppose we can get a proper handle on costs - that still leaves the bigger issue of who will cover the costs - in other words who pays? This is a big topic to say the least. It also touches on one of the other things that Neil mentioned - a common bit of feedback that 4C receives isn't about costs at all - it's about value and benefits. If the benefits can't be defined for curating and keeping content then how can you build a business case to cover the costs? It doesn't matter how well articulated, calculated and compared the costs might be - if they aren't justifiable then the money needed to cover them won't be found. It would be easy to go down the route of suggesting a Value Exchange to go alongside the Cost Exchange, although probably not tractable within the timeframe or scope of the project.
But perhaps there is another bit of cost information that could be captured in CCEx which would be illuminating - the 'cost of creation' to go alongside the 'cost of curation'. This provides some context to curation costs and gives a clue to how make arguments for sustainable cost recovery. As an example, the KRDS project had an interesting case study from the University of Oxford that compared the cost of curation of research data with the cost of doing that research in the first place. Creation is a 73% of the total costs, initial curation is 24%, and finally long-term storage and management is a mere 3% [1]. This means that curation and preservation are in effect a marginal cost compared with creating the data in the first place. And if they are a marginal cost then does that mean the costs can be included in the budget for creating the data in the first place? In the UK for research data the answer to this question is now yes.
Maybe the same is true in other fields? How do the costs of curation compare with the costs of creation for other types of content? I did some back of the envelope calculations and came up with the table below. I followed Neil's advice from his presentation and did the simplest possible cost modelling I could. In the spirit of openness, the spreadsheet is available if you want to see what I did - but don't get over excited, there's a limit to what I could get done on the train home from Birmingham. It might have more holes in it than Swiss Cheese but it's a start!
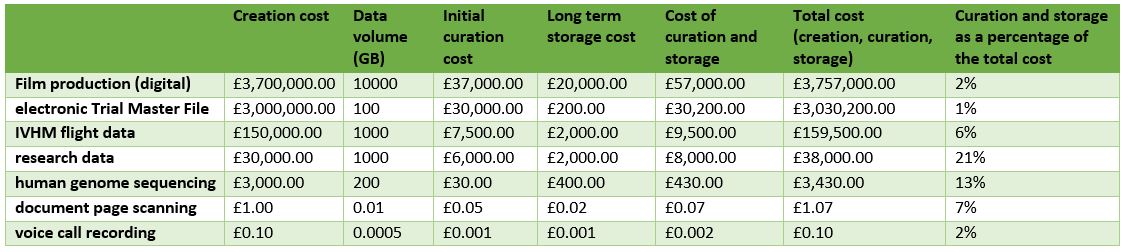
This shows a common trend - curation and preservation is a marginal cost compared to the original creation of the data for many disciplines. So does this point to making a case for recovery of the costs of curation from the budgets for creation? Maybe - for the very simple reason that the budgets are big enough, which is more than can be said for many archives that are dissociated from content creation - often their budgets don't even come close to covering their real costs! Pushing preservation upstream as close as possible to the point of content creation makes a lot of sense, and so too, I suspect, is recovery of the costs. Indeed it could be the only sustainable option. Knowing the ratio between cost of creation and cost of curation helps identify whether this might be a fertile hunting ground. Models where the 'creator pays' rather than the 'consumer pays' also fit well in a world where there is a growing expectation of content being free at the point of use. It also fits with the model of 'get the money whilst you can'.
This doesn't solve the problem of needing a business case - value still has to be identified - but it does help in identifying where to target such a business case and its cost/benefit analysis. We're just starting to see examples of this in Research Data Management. Data.bris at the University of Bristol showed that proper Research Data Management has a positive return [2]- 1% increase in funding rates. This might sound small, until you realise they have £120M a year in research income so this means £1M+ on the bottom line for the University. Better still, the costs of RDM are recoverable from the grants under funding rules. So not only can curation be built into the budgets for research data 'creation', it has a net economic gain for the institution, which makes the whole thing sustainable - as they say 'what's not to like'. It would be fascinating to see if a comparison of the 'cost of creation' to 'cost of curation' could help identify where other organisations and sectors could take a similar approach.
[1] http://www.jisc.ac.uk/media/documents/publications/reports/2010/keepingresearchdatasafe2.pdf
[2] http://data.bris.ac.uk/files/2013/06/data-bris-benefits-report-V2.pdf
[4] http://en.wikipedia.org/wiki/Apples_and_oranges
[5] http://en.wikipedia.org/wiki/Pear-shaped
Matthew Addis, Arkivum
Matthew is part of the 4C Project Advisory Board and repesents Service Providers and Curation Expert. He has spent 15 years leading a diverse portfolio of industry-led applied research projects including archiving and digital preservation, service-oriented computing, data mining and knowledge management to name but a few.

